How We Built an Interactive Flutter Course using Kubernetes
Web frameworks have many interactive online courses where you can write code directly in the browser. But something like this has never existed for Flutter. We wanted to be the ones to make it happen.
However, this would have cost us almost a thousand dollars every month. But then we learned Kubernetes.
This site you are on right now is an Astro website hosted on Vercel and it uses Turso as the database.
However, it gets much more complicated when we enter the interactive demo. The entire infrastructure within the course runs on Kubernetes, specifically k3, which is a lightweight version of Kubernetes.
By using Kubernetes, we can have a fully interactive Flutter course where you run Flutter apps in the browser (within a tailored learning experience).
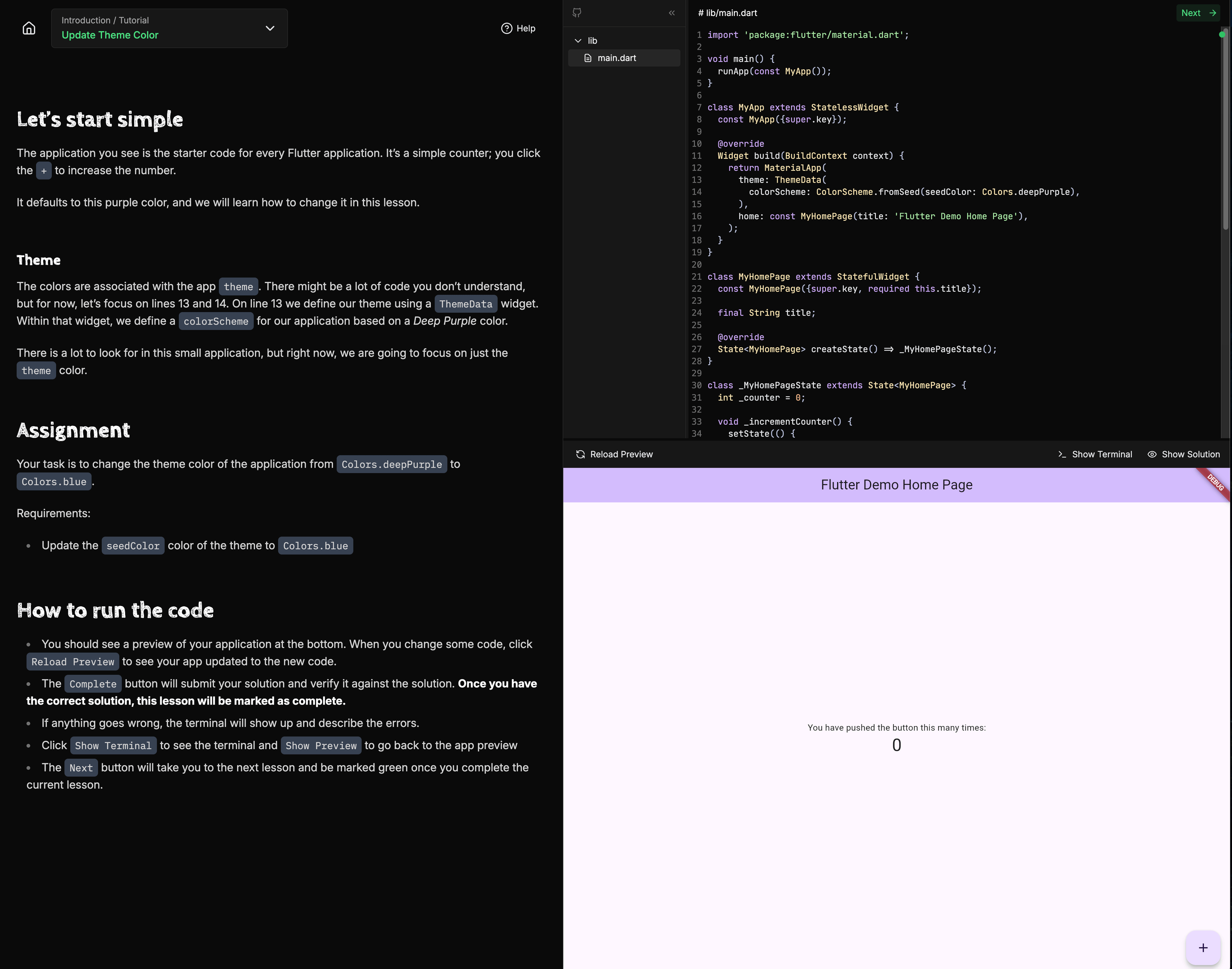
Now, how did we get to this point, and why did we use Kubernetes?
It’s expensive to run long-running jobs
Our goal for The Best Flutter Course was for each individual to have their own Flutter instance, where they can compile and run their Flutter apps. To do this they will need a connection to a server with long-running jobs and in some cases very long-running jobs.
Our first PoC was a node service deployed to fly.io.
Resource Requirements and Cost Estimation
Every job is created to compile and run Flutter. Because of this, the resource usage can vary significantly, typically ranging from 700 MB to 1.5 GB of memory per job for reliable operation.
If we aim to support 60 concurrent users, we should plan for the upper limit of memory usage which would be 90 GB.
60 jobs × 1.5 GB = 90 GB of memory requiredBased on this requirement, the pricing for a machine capable of handling that load would be approximately $976/month.
Additional Considerations: LSP and Cold Starts
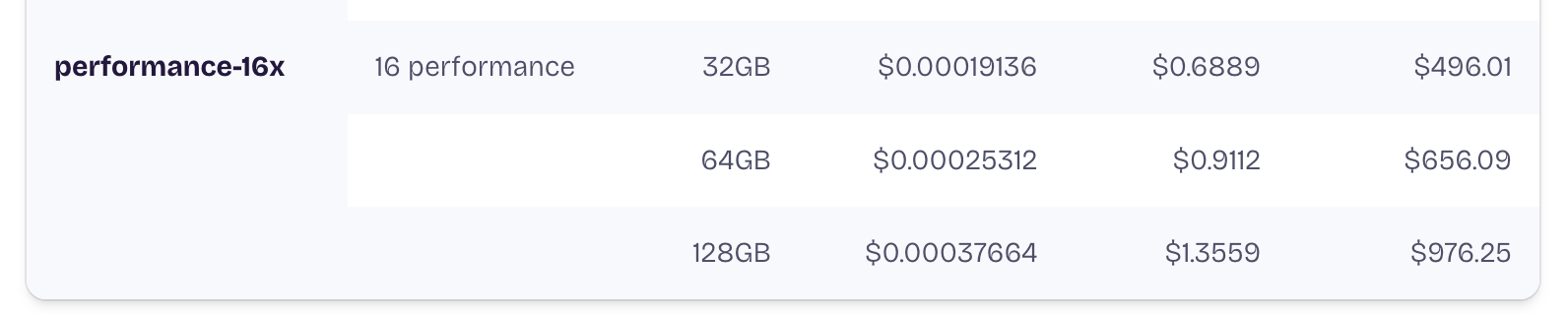
This calculation above does not account for other features we want to add. For example, if we want the red squiggly lines when your code is incorrect, we need a Language Server Protocol (LSP). When LSP is included, the memory usage per user increases to approximately 3 GB, bringing the total requirement to 180GB.
60 users × 3 GB = 180 GB of memory requiredFor this, we would need multiple machines, which would increase the pricing even more.
It’s also important to note that pricing is based on the instance being active, not on the total usage. Even if only one user is active for the entire month, the cost remains the same, you pay for the running instance, not the amount of resources consumed.
Issues with Fly.io
This brings up two specific issues when we tried experiementing with Fly.
Issue #1: Instance-Based Pricing
- You’re charged for uptime, not usage.
- Costs remain fixed regardless of how many users are active.
Issue #2: Cold Starts
To help mitigate costs, Fly.io offers automatic “pausing” of idle devices, which reduces memory and compute usage. However, this introduces a serious tradeoff: cold starts.
If you’re the first user to trigger a Flutter job after a pause, you’re not facing a typical 10-second startup, but something closer to 50 seconds, an unacceptable delay for the experience we wanted to deliver.
Renting our server
Given the high cost and cold start issues, the experience we wanted to build seemed unrealistic, at least without raising VC funding.
But then we received a recommendation to try Hetzner, which is a dedicated server that we would have to manage ourselves. This was definitely out of our comfort zone, but what you can get for the price you pay was insane:
- 128 GB of RAM
- Better performance than Fly.io
- At ~1/20th the cost
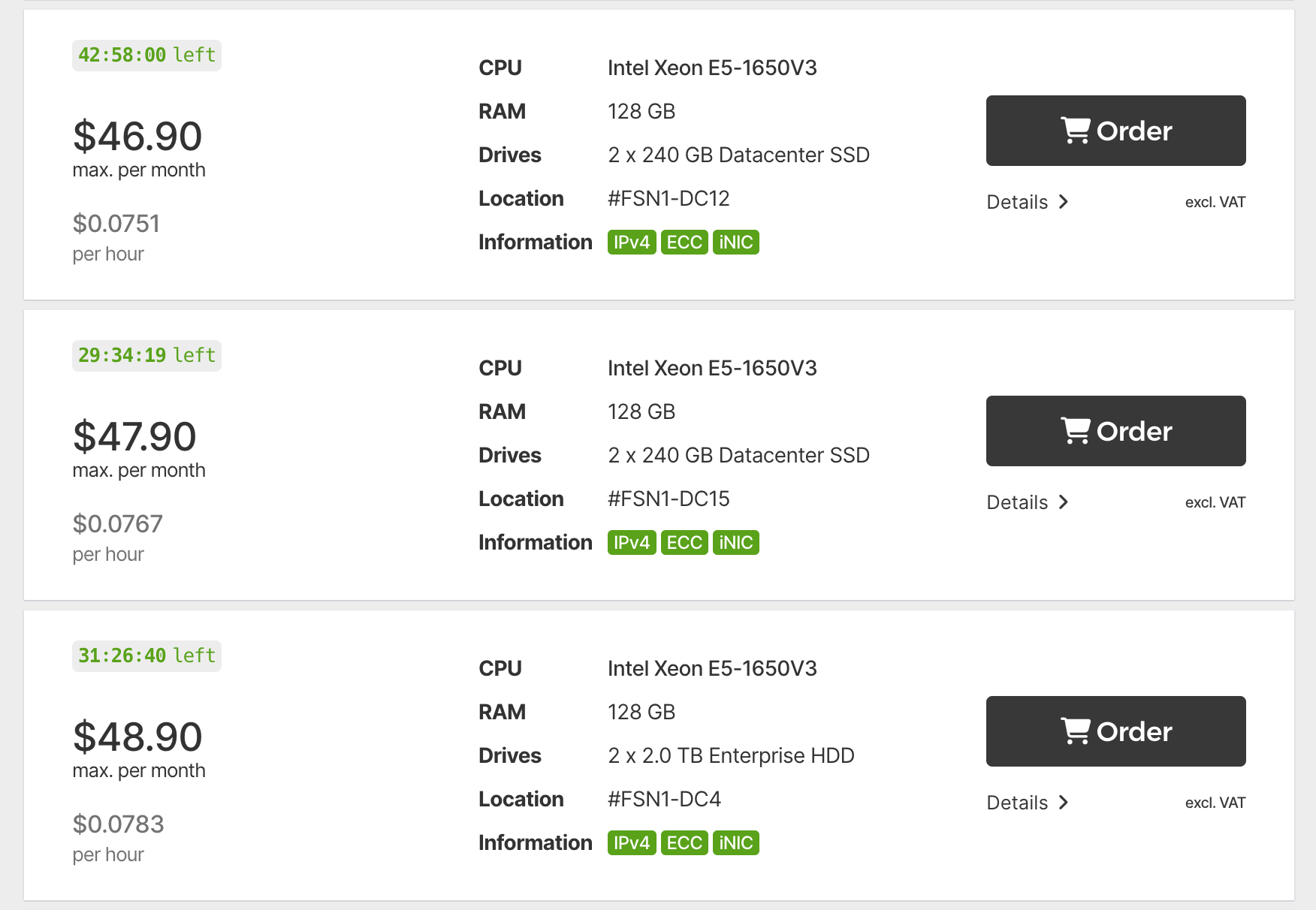
So we decided to pull the trigger and go for it.
We paid approximately $50/month for our first test server, compared to the ~$976/month from Fly.io.
This is where our Kubernetes journey started.
High-level Kubernetes setup
When using Kubernetes, there is a lot that is needed to get the setup you desire, but it’s mostly a 1 time thing set up that you do with lot of configuration files, that you can reuse in the future.
I am going to be honest, it’s A LOT to learn when you don’t have experience in infrastructure. But after you get past the initial hurdle you start to see a lot of potential that you couldn’t think of when only working with managed solutions.
Here is a high level of the steps we took.
- ssh into the Linux server with the credentials we got from Hetzner
- Installing kubectl, helm, and k3
- Installing metalLB, Nginx Ingress, cert manager (Let’s encrypt)
The structure of configuration files looks something like this (this is a minimal example and missing files for simplicity)
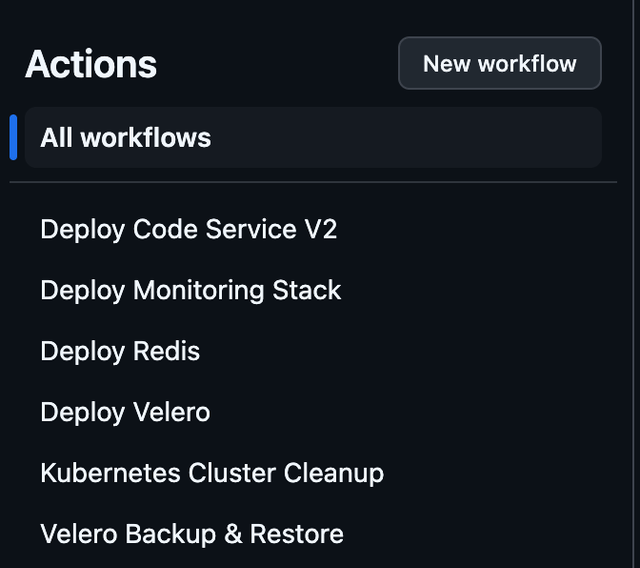
That is the overall structure of our Kubernetes cluster, which runs the Flutter jobs. We also set up GitHub Actions to remotely trigger various actions such as installing a specific service with a new docker image. This is referred to as GitOps.
The service that is running all code compiling for the Hungrimind platform is called “code service”. We use git as our source of truth, any change to the code service will automatically trigger a GitHub action that triggers another GitHub action in the cluster repository to deploy the code service.
Here is an example of the complete workflow:
Manually push changes to our Code Service → GitHub Action builds and uploads to docker → GitHub action notifies our k3 repository → automatically deploys that docker version to the cluster.
Of course, we can manually trigger deployments as well.
What is helm, metalLB, ingress and cert manager?
We previously mentioned a bunch of words that probably went over your head if you don’t already know the basics of Kubernetes: Helm, MetalLB, Ingress, and Cert-Manager. Each of these plays a key role in making Kubernetes clusters easier to manage and production-ready.
Helm is often described as the package manager for Kubernetes. It helps you define, install, and upgrade applications in your cluster using “charts” (basically, pre-configured templates that simplify complex setups).
MetalLB is used when you’re running Kubernetes on bare metal (without a cloud provider). Since cloud environments typically offer built-in load balancers, MetalLB fills that gap by providing a network load balancer for bare-metal clusters, allowing services to be exposed externally.
Ingress is all about managing access to your services. Instead of exposing every service with its own IP or load balancer, Ingress lets you define routing rules—like domain names and paths, so you can consolidate traffic through a single entry point.
Cert-Manager automates the management of TLS certificates in Kubernetes. It can request certificates from providers like Let’s Encrypt and handle renewals, making it easier to secure your services without a lot of manual effort.
Flutter job service (internally called code-service-v2)
Until now, we have talked mostly about the setup to have our server running in a secure and scalable way. This next part is the code service that powers the Hungrimind platform.
There is an API written in Go, and all endpoints require a JWT signed with Hungrimind’s private key for authentication.
This ensures that when our website sends a request to create a job, you are put into a queue.
Depending on the queue and our currently available “slots” of jobs, it will securely trigger Kubernetes to deploy a new pod. Each pod includes everything needed for the job, such as the Flutter instance, ingress configuration, and more. Once the pod is deployed, a unique URL is generated that points to the Flutter preview, which is then displayed on the website.
The Flutter preview in this case is a web-server command that looks something like this:
exec.Command("flutter", "run", "-d", "web-server", "--web-port", "8080", "--web-hostname", "0.0.0.0")The reason we are running a debug server is to allow the user to run hot restarts of the web preview whenever they want to see their changes.
So in short, we have two docker images: one for the API and one for the individual Flutter job.
LSP
We later implemented something called an LSP which is the “Language Server Protocol”. This allows our code editor to have autocompletion, code actions, and hover definitions.
Since this is another task running in the job instance, the memory usage grew. Now, each job is somewhere between 2-3GB memory usage.
Luckily this is still not that expensive on dedicated servers.
Monitoring
Similar to all the other services on the cluster we also have Grafana and Prometheus. They are used together for monitoring everything running on the cluster, such as:
- queues
- jobs
- resources
- logs from all services
This is done by creating a dashboard, this dashboard shows us the above information and links to relevant logs for those users. When somebody has issues, they can give us their support ID, we can find their job and all related logs to that instance so we can solve their problem faster.
Why did we do all this?
A course is a high-maintenance product. Lots of topics get deprecated so we NEEDED a way to build this in a way where updates were easy. Now, to update the course two things need to be done:
- Update the lesson content (this is a markdown file)
- Update the code (this is a GitHub repo with an “initial” and “solution” folder).
This infrastructure allows us to keep the course up to date, while at the same time providing a unique experience of writing your Flutter apps directly in the browser and having your code verified to make sure you are actually learning.
We pay the same attention to detail with our app architecture as we do with this platform. To learn more, check out how we implement MVVM Architecture in our production applications.
Get Articles in Your Inbox
Sign up to get practical tutorials and production patterns delivered to your inbox.